Multimodal/Contrastive Learning, or CLIP from Scratch
Now that we’ve gone over text transformers and vision transformers, I wanted to move on to CLIP which is text-image pairs. In hindsight, this paper really is a natural follow-up to both, since it uses both a text and vision transformer as components. I will be referencing Learning Transferable Visual Models From Natural Language Supervision by Radford et al. 2021 for my implementation.
Let’s get started!
Intro and Motivating Work
So, in the last post I talked briefly about how the training for the ViT was done using ImageNet and other labelled datasets. The authors of this paper point out that in NLP, pretraining data has shifted from these kinds of high-quality crowd-labeled datasets to using web-scale collections of text. The intuition then is that computer vision could also take advantage of this large amount of available text to help inform the task of image classification. Specifically, the authors mention the potential of “using natural language supervision for image representation learning”, which was still rare at the time of publication. CLIP, or Contrastive Language-Image Pre-training, seeks to test this method of natural language supervision for image learning.
The authors find that this method of changing the learning objective from predicting a certain class to a contrastive objective of finding which text-image pairs match has better rates of transfer to different datasets.
Overall Approach
Data
So the authors of this paper had to curate their own dataset called WebImageText which is created by searching for image, text pairs from a list of 500,000 queries. They mention that the resulting dataset has a similar total word count as the dataset for GPT-2.
Training method
So, this paper makes a key innovation in the pretraining stage which allows for much better performance. In previous works with natural language supervision, the text transformer is trained to predict the exact caption of an image. However, since this task of captioning is pretty complex, the authors found they had issues with scaling this approach.
Instead, they use a proxy task of predicting which text as a whole is paired with which image, or changed the predictive objective to the contrastive objective.
In other words, “given a batch of N (image, text) pairs, CLIP is trained to predict which of the NxN possible (image, text) pairings across a batch actually occurred”. This is done by learning a multi-model embedding space, or an embedding space which expresses properties of both the text and the image. This space is obtained by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings which are actually paired and minimize the cosine similarity between the image and text embeddings which are not paired.
Basically, if we have the following image, text pairs:
(cat, image of cat)
(dog, image of dog)
(bear, image of bear)
We want to maximize the cosine similarity between the embeddings of cat, image of cat and minimize the cosine similarity between dog, image of cat and bear, image of cat, and similarity for the other images.
Cosine similarity
The cosine similarity between two embeddings is defined as the cosine between the two vectors. We can use the formula, |a|x|b|xcos(theta) = a dot product b and rearrange it to get
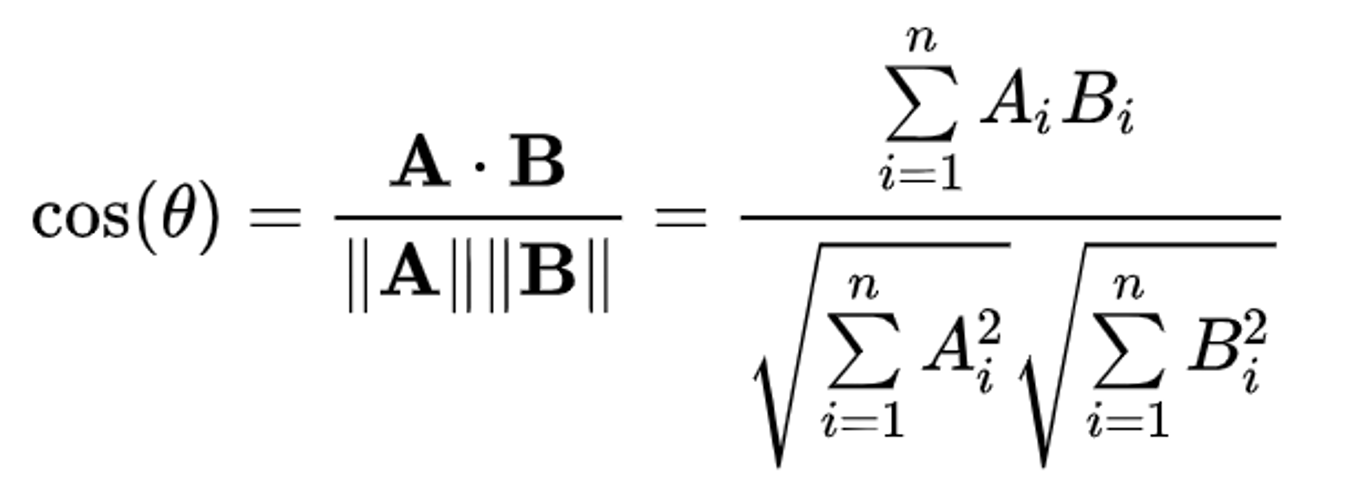
Intuitively, if we think of each value in the embedding vector as an expression of a property, then closer embeddings will have a smaller cosine between the vectors in high-dimensional space.
So let’s say that we have 3-dimensional embeddings— in this simplified example, the first dimension could be how domesticated the thing is, the second could be how big the thing is, and the third could be how loyal the thing is.
So, if we express cat, dog, and bear in this system, we could get something like the following embeddings:
cat: <0.8, -0.2, -0.3>
dog: <0.9, 0.5, 0.7>
bear: <-0.8, 0.8, 0.5>
The embedding between cat and dog would have a cosine similarity of 0.29, and bear and dog would have a cosine similarity of 0.077. Thus, we would say that cat and dog are more similar than bear and dog.
In the case of CLIP, we not only have embeddings for the text descriptions but also the images, and then try to match them with cosine similarity.
Architecture
The general architecture of the model is that there is a text encoder which encodes natural language description and an image encoder which encodes an image. The authors then use a linear projection to map the encoder representation to a multi-modal embedding space.
The authors try two architectures for the image encoder, the ResNet architecture and the ViT, which was newly introduced at the time. The text encoder is a text transformer, which uses masked self-attention because the authors wanted to allow for initializing the transformer with pretrained models (which are decoder-only).
They find that the best performing architectures were using an image transformer and text transformer.
Thus, because we already went over how to make an image transformer and text transformer, the implementation of this model is relatively straightforward and reuses a lot of concepts we have already seen.
Implementation
Image and Text encoders
This section will just be mostly reusing code that we already went through when making a text and vision transformer.
Let’s start with the building blocks of both transformers, which are attention, multi-headed attention, MLP, and blocks.
Attention Head
#we use this for the text transformer
class MaskedHead(nn.Module):
def __init__(self, head_size, embd_dim):
super().__init__()
self.key = nn.Linear(embd_dim, head_size, bias = False)
self.query = nn.Linear(embd_dim, head_size, bias = False)
self.value = nn.Linear(embd_dim, head_size, bias = False)
self.register_buffer('tril', torch.tril(torch.ones(block_size,block_size)))
def forward(self, x, targets):
B, T, C = x.shape
k = self.key(idx)
q = self.query(idx)
v = self.value(idx)
wei = q @ k.transpose(-2, -1) * C**-0.5
wei = wei.masked_fill(self.tril[:T,:T] == 0, float('-inf'))
wei = F.softmax(wei, dim = -1)
out = wei @ v
return out
#we use this for the vision transformer
class UnmaskedHead(nn.Module):
def __init__(self, head_size, embd_dim):
super().__init__()
self.key = nn.Linear(embd_dim, head_size, bias = False)
self.query = nn.Linear(embd_dim, head_size, bias = False)
self.value = nn.Linear(embd_dim, head_size, bias = False)
def forward(self, x):
#no mask because encoder
k = self.key(x)
q = self.query(x)
v = self.value(x)
wei = q @ k.transpose(-2, -1) * D ** -0.5
return F.softmax(wei, dim = -1) @ v
Multi-headed attention
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, embd_dim, masked = False):
super().__init__()
head_size = embd_dim // num_heads
if masked:
self.heads = nn.ModuleList([MaskedHead(head_size) for i in range(num_heads)])
else:
self.heads = nn.ModuleList([UnmaskedHead(head_size) for i in range(num_heads)])
self.proj = nn.Linear(embd_dim, embd_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([head(x) for head in self.heads], dim = -1)
return self.dropout(self.proj(out))
MLP/Feed Forward layer
class FeedForward(nn.Module):
def __init__(self, embd_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(embd_dim, 4*embd_dim),
nn.GELU(),
nn.Linear(4*embd_dim, embd_dim),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
Block
class Block(nn.Module):
def __init__(self, n_head, embd_dim, masked = False):
super().__init__()
self.mha = MultiHeadAttention(n_head, masked)
self.mlp = FeedForward()
self.ln1 = nn.LayerNorm(embd_dim)
self.ln2 = nn.LayerNorm(embd_dim)
def forward(self, x):
x = x + self.mha(self.ln1(x))
x = x + self.mlp(self.ln2(x))
return x
Encoder/Decoder Transformer
class Encoder(nn.Module):
def __init__(self, n_head, n_blocks, embd_dim, masked = False):
super().__init__()
self.blocks = nn.Sequential(*[Block(n_head, embd_dim, masked) for _ in range(n_blocks)])
self.layernorm = nn.LayerNorm(embd_dim)
def forward(self, x):
return self.layernorm(self.blocks(x))
Vision + Text transformers
Now, let’s add the separate classes for the vision transformer and the text transformer, which differ from our previous implementations in that:
- the output of both must be an encoding
- the way that the text transformer’s encoding is done is very similar to that of the vision transformer, in that the text sequence is bracketed by start and end of sentence tokens ([SOS], [EOS]) and the final encoding is just the value of the EOS token at the last layer of the text transformer.
Here is the implementation of the vision transformer, which is basically the same except the authors add an additional layer norm after the positional encodings and patch embeddings are added together.
class ViT(nn.Module):
def __init__(self, patch_size, vit_heads, vit_blocks, vit_embd):
super().__init__()
D = vit_embd
#patch embedding
self.patch_embedding = lambda x: x.reshape(B, N, P**2*C)
#extra position (N ---> N+1) because of CLASS token
self.pos_emb = nn.Parameter(torch.zeros(1, N+1, D))
nn.init.normal_(self.pos_emb, std = 1e-6)
self.cls_emb = nn.Parameter(torch.zeros(1, 1, D))
nn.init.normal_(self.cls_emb, std = 1e-6)
self.proj = nn.Linear(P**2*C, D)
self.encoder = Encoder(vit_heads, vit_blocks, D, masked = False)
#add additional layer norm before combined patch and position embeddings
self.ln = nn.LayerNorm(D)
#no classification head since we want the raw embedding
def forward(self, idx, targets):
patches = self.patch_embedding(idx) #(B, N, P^2*C)
#expands the embedding to have a batch dim
cls_emb = self.cls_emb.expand(B, -1, -1) #(B, 1, 1)
#project patches to token dimension
patches = self.proj(patches) #(B, N+1, D)
#concatenate the class embedding to the front of the patches in the N dimension
x = torch.cat((cls_emb, patches), dim = 1) #(B, N+1, D)
#add the position embedding to keep positional info
x = x + self.pos_emb
#pass through extra layernorm
x = self.ln(x)
#pass x through the encoder
x = self.encoder(x)
#return the raw CLASS token activation
activations = x[:,0,:]
return activations
Here’s the slightly modified text transformer class to return the value of the activations corresponding to the [EOS] token.
class TextTransformer(nn.Module):
def __init__(self, vocab_size, lm_heads, lm_blocks, lm_embd):
super().__init__()
#vocab_size should include [SOS] and [EOS] tokens
self.token_embedding_table = nn.Embedding(vocab_size, lm_embd)
self.position_embedding_table = nn.Embedding(block_size, lm_embd)
self.encoder = Encoder(lm_heads, lm_blocks, lm_embd, masked = False)
#no projection head back to vocab_size
#layer normalize the [EOS] token feature before returning
self.ln = nn.LayerNorm(lm_embd)
def forward(self, idx, targets):
tok_emb = self.token_embedding_table(idx)
pos_emb = self.position_embedding_table(torch.arange(T, device = device)) #(T,C)
x = tok_emb+pos_emb
x = self.encoder(x)
#return value of [EOS] activations after layer normalization without projecting back to vocab_size
return self.ln(x[:, -1, :])
Making the CLIP model
Now that we have the text and image transformer classes, we can use them within our overall CLIP model. We just need to map the encodings using a learned projection to the same multi-modal embedding dimension and compute the cosine similarities/loss between the pairs of the two modalities.
Here’s the code for doing this, which is also relatively straightforward.
class CLIP(nn.Module):
def __init__(self, vocab_size, lm_heads, lm_blocks, lm_embd, patch_size, vit_heads, vit_blocks, vit_embd, m_embd):
self.text_encoder = TextTransformer(vocab_size, lm_heads, lm_blocks, lm_embd)
self.img_encoder = ViT(patch_size, vit_heads, vit_blocks, vit_embd)
#learned temperature parameter which scales the cosine similarities
self.t = nn.Parameter(torch.as_tensor([1.]))
#learned text/image projection matrix
#m_embd is the dimension of the multimodal embedding
self.text_proj = nn.Linear(lm_embd, m_embd)
self.img_proj = nn.Linear(vit_embd, m_embd)
def forward(self, img_batch, text_batch):
#batch dimension
B = img_batch.shape[0]
#find image and text embeddings in multimodal dimension and normalize
I_e = F.normalize(img_encoder(img_batch))
T_e = F.normalize(text_encoder(text_batch))
#calculate scaled cosine similarity
logits = (I_e @ T_e.T) * torch.exp(self.t) #(m_embd, m_embd)
#calculate symmetric loss function
labels = torch.arange(B)
loss_i = F.cross_entropy(logits, labels)
loss_t = F.cross_entropy(logits.T, labels)
loss = (loss_i + loss_t)/2
return logits, loss
With that, the architecture implementation of CLIP is complete! I did not really go into the data processing step in this blog, but it consists mostly of allowing retrieval of image-text pairs and composing these into batches, which is relatively straightforward. I may do a blog in the future on dataloaders which probably will be enough to implement this part of the model training.
Concluding Remarks
Choosing this paper after vision and text transformers was rather coincidental but it definitely worked out very well, since this paper is basically nearly just a clever combination of a text transformer and a vision transformer.
The main experiment/advance of CLIP models are its transfer capabilities to unseen datasets/tasks. Specifically, since CLIP is not trained to predict classes but rather output the cosine similarity between a natural language description and an image, CLIP can be used to generalize to any class that could be expressed within the vocab that it is trained on theoretically, since one can just take the highest cosine similarity class in a dataset to a given image.
However, in reality it is not as simple as just that. Specifically, because CLIP uses natural language inputs which are in the form of queries which are full sentences rather than single class names, its performance can improve through prompt engineering to match its training distribution. The paper states that the prompt template “A photo of a {label}” is a good default description.
Additionally, the authors mention the problem “polysemy”, where some class names could have multiple names, such as “boxer” referring to a type of athlete or a type of dog in the Oxford-IIIT Pet datset. In this case, prompt engineering such as “a photo of a {label}, a type of pet.” for domain specific datasets helped perform performance.
Another thing that the authors do to improve performance is to not just feed a single prompt into the model but an ensemble of prompts, which then “vote” on the best class. This method improves performance by 3.5%.
There’s also an in-depth discussion on the impacts of CLIP on measuring distribution shift, particularly for models trained on the ImageNet dataset. Basically, good performance on ImageNet does not necessarily mean good performance on all images, because the models could be learning spurious connections rather than how to actually identify objects. For example, the models could learn to identify a class by the lighting in the images rather than the images themselves. Because CLIP is not trained on the same dataset, the authors point out the potential for using it as a way to investigate the robustness of models primarly trained on ImageNet. This discussion is pretty long and also very interesting, so I’ll just link the article here.
Anyways, I definitely learned a lot about contrastive learning/CLIP through writing this article and I hope you did too. Thanks for reading!